Puppet Dataset Results
This page includes:
Description
Testing Set
*on the task of distinguishing puppet parts from background
- Section
from the paper describing the data and the models
- Training
set pictures
- Testing
set pictures
- Comparison
to Support Vector Machines
Description
|
|
Overview We tested our scan segmentation algorithm on a challenging dataset of cluttered scenes containing articulated wooden puppets. The dataset was acquired by a scanning system based on temporal stereo [1] (displayed on the left). The system consists of two cameras and a projector, and outputs a triangulated surface only in the areas that are visible to all three devices simultaneously. Each scan had around 225,000 points, which we subsampled to around 7,000 with standard software. Our goal was to segment the scenes into 4 classes --- puppet head, limbs, torso and background clutter. Point Features We used spin-images[2] as local point features. The spin-images were computed on the original high-resolution surface. The spin-images were of size 10 x 5 bins at two different resolutions. We scaled the spin-image values, and performed PCA to obtain 45 principal components. We added a bias feature (set to 1 for all points). Edge Features We use the surface links output by the scanner as edges in the MRF. We obtained the best results by using a single bias feature (set to 1 for all edges). |

Training Set
We used 5 labeled scenes involving the puppet and various other objects for training the algorithm. The scenes are displayed below. Please click on the thumbnails to view the enlarged images.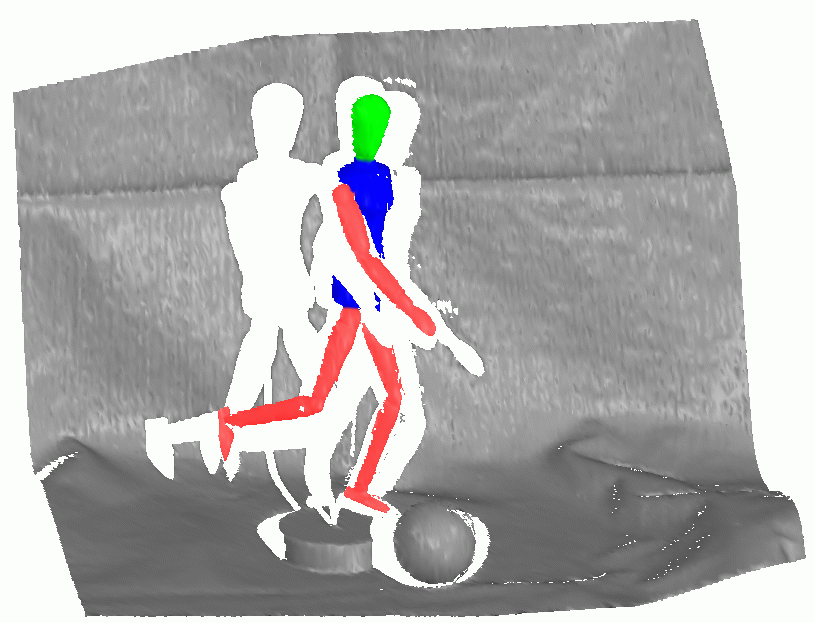 Scene 1 |
 Scene 2 |
 Scene 3 |
 Scene 4 |
 Scene 5 |
{kind=link}
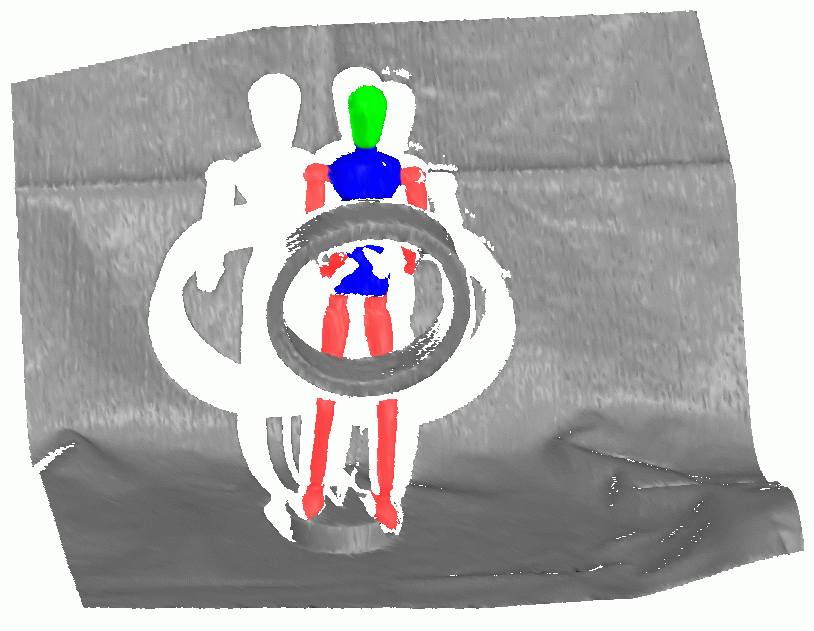
Testing Set
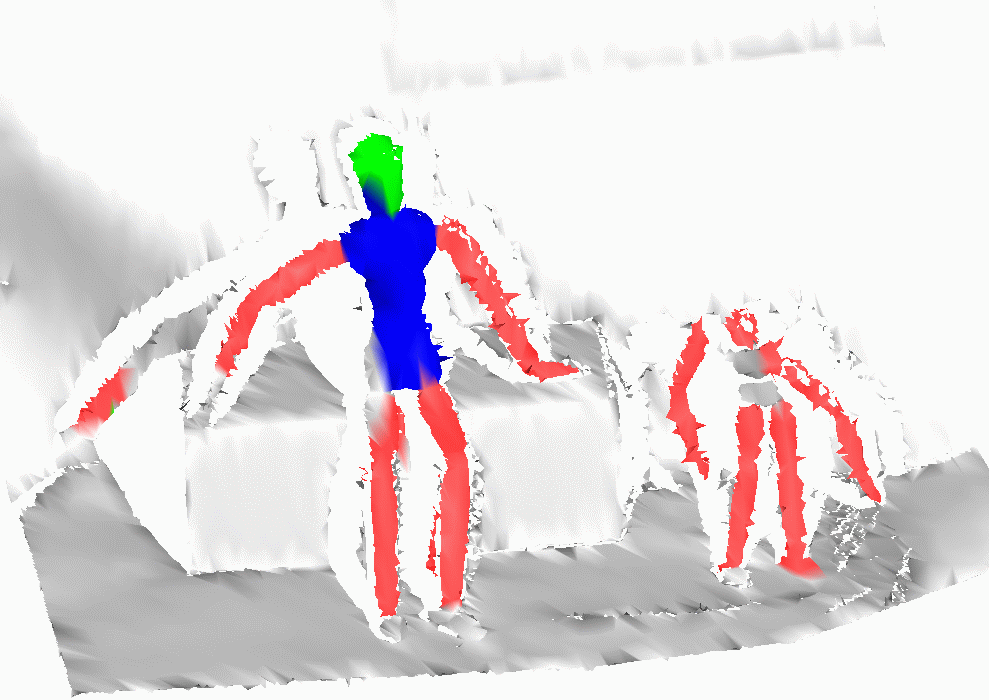 Scene 1 |
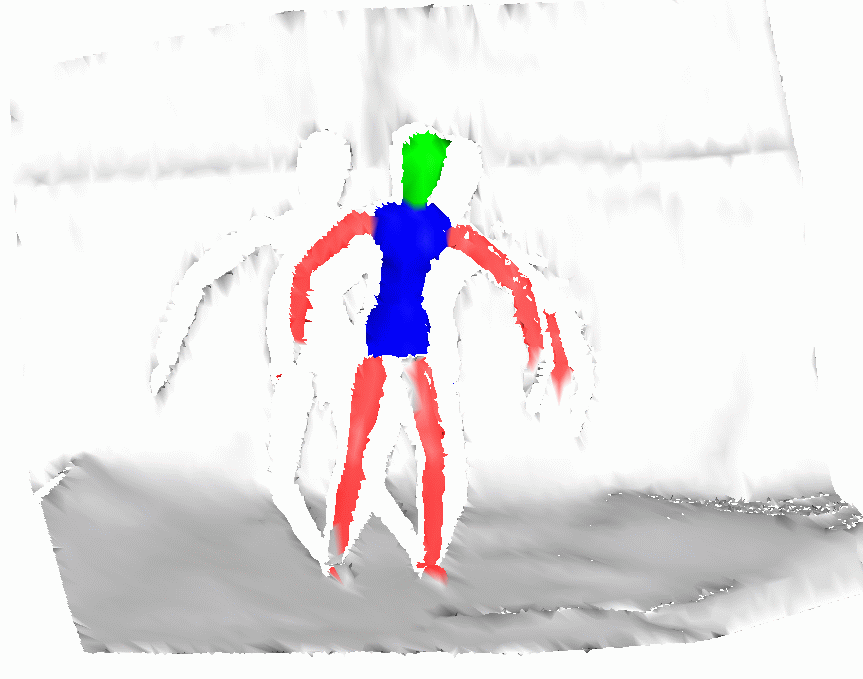 Scene 2 |
 Scene 3 |
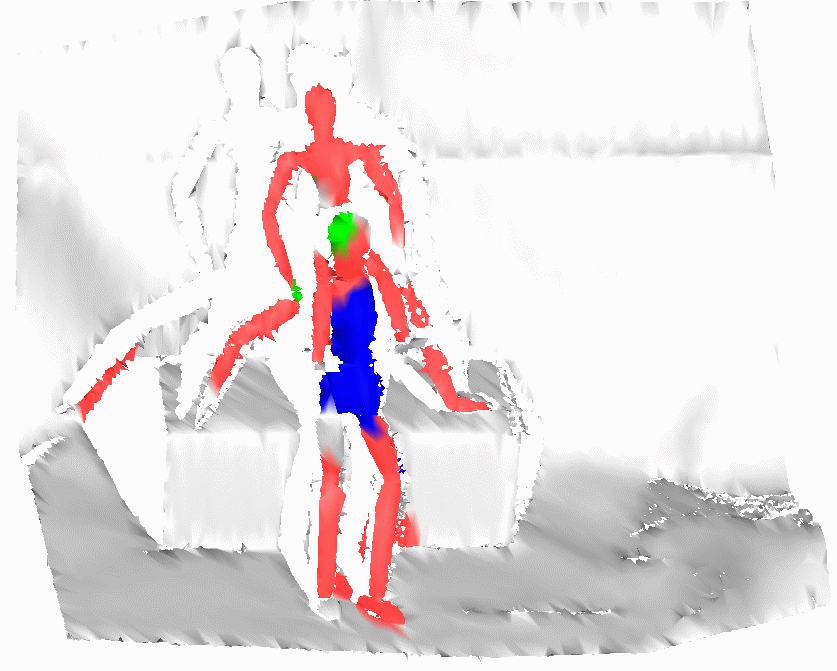 Scene 4 |
 Scene 5 |
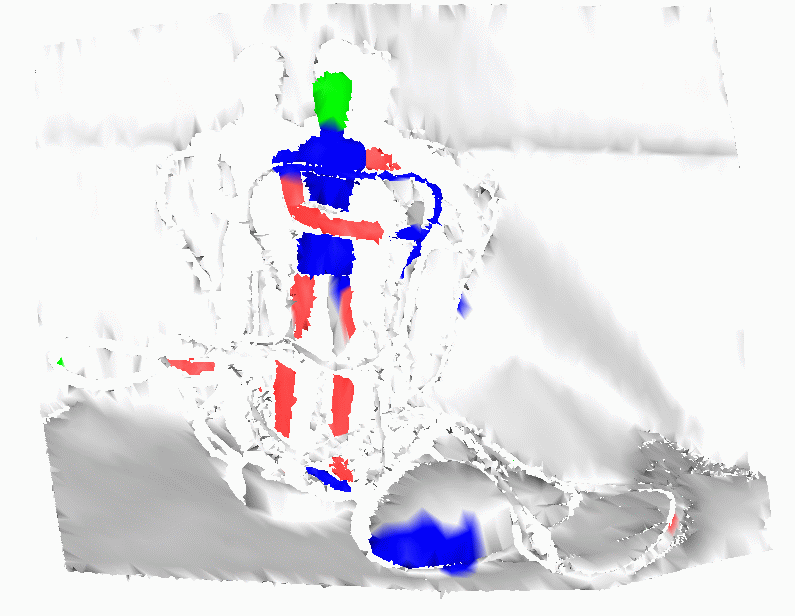 Scene 6 |
Comparison to SVM
We compared our Maximum-margin Associative Markov Nets (MM-AMN) method to Support Vector Machines which classify each scan point separately (SVM). Another common approach is to take the labels produced by SVM and determine the label at each point by having its neighbors vote (Voted-SVM). All three methods used the same node features.| Results |
AMN |
SVM |
Voted-SVM |
| Training set accuracy |
97.97% | 88.54% | 88.25% |
| Testing set accuracy |
94.41% | 87.17% | 86.50% |
| Precision on testing set* |
86.84% |
93.35% | 99.51% |
| Recall on testing set* |
83.88% | 18.56% | 11.65% |
SVM-based methods which classify each
point independently perform much worse than our approach, producing
very low recall on both the training and the testing set (see example
below). This poor performance is caused by the relatively small
spin-image size which can make the algorithm more robust under clutter
and occlusion, but at the same time can make it hard to discriminate
between locally similar shapes. The dataset has significant shape
ambiguity, as it is very easy to confuse sticks for limbs, and the
torso for parts of the computer mouse appearing in the testing set.
To understand the reason underlying the superior performance of the AMN, we ran a flat classifier with node weights trained for the AMN model. The result (shown in picture d) above) suggests that our algorithm has an additional degree of flexibility --- it can commit a lot of errors locally, but rely on the edge structure to eliminate the errors in the final result. This result demonstrates that our approach would be superior to a strategy which trains the edge and the node parameters separately.
[2] A. Johnson and M. Hebert. Using spin images for efficient object recognition in cluttered 3D scenes. In proc. IEEE PAMI, volume 21, pages 433-449, 1999
a) AMN Result |
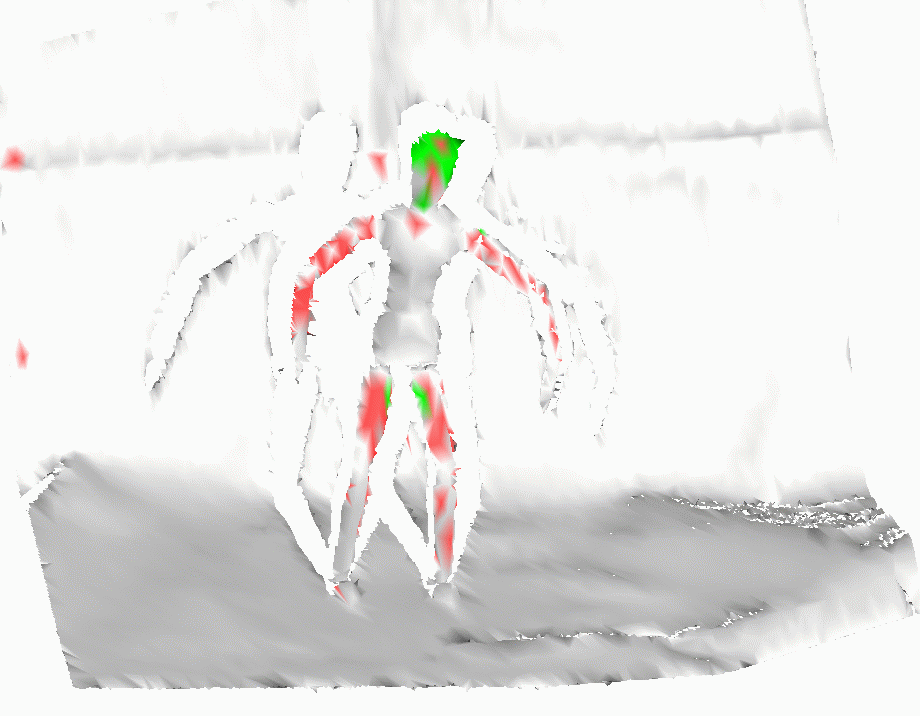 b) SVM Result |
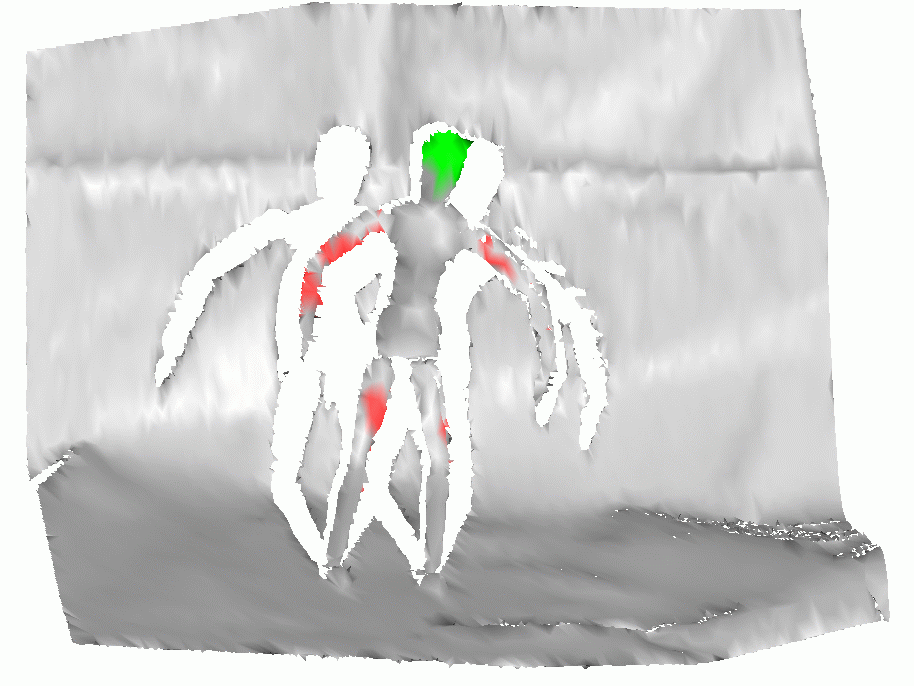 c) Voted-SVM result |
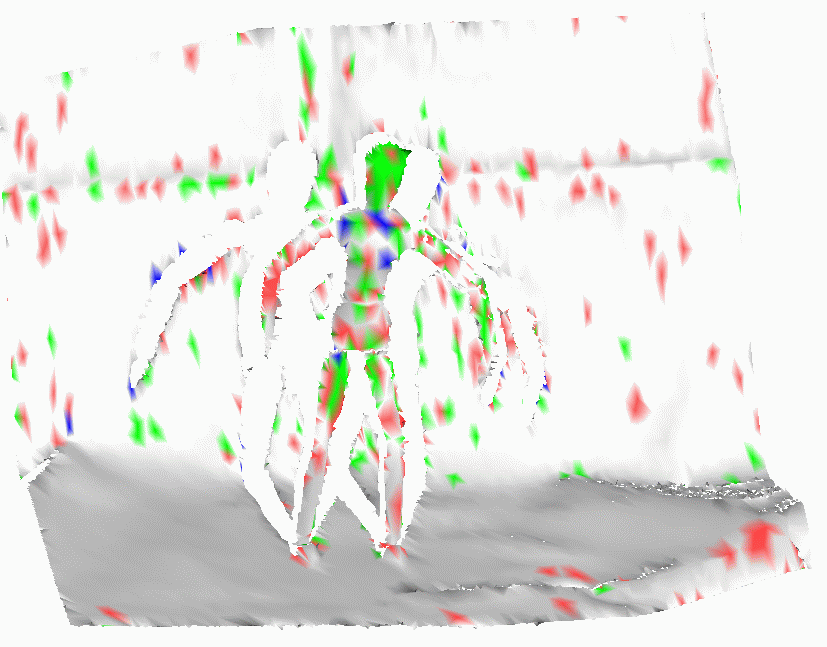 d) Result of running AMN without edges |
To understand the reason underlying the superior performance of the AMN, we ran a flat classifier with node weights trained for the AMN model. The result (shown in picture d) above) suggests that our algorithm has an additional degree of flexibility --- it can commit a lot of errors locally, but rely on the edge structure to eliminate the errors in the final result. This result demonstrates that our approach would be superior to a strategy which trains the edge and the node parameters separately.
Bibliography
[1] James Davis, Ravi Ramamoorthi, and Szymon Rusinkiewicz. Spacetime stereo : A unifying framework for depth from triangulation. In proc. CVPR, 2003.[2] A. Johnson and M. Hebert. Using spin images for efficient object recognition in cluttered 3D scenes. In proc. IEEE PAMI, volume 21, pages 433-449, 1999