| | ||||
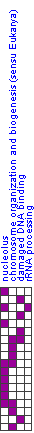 |
|
|||
 >4x >4x |
Module 392 -- rRNA processing and DNA repair |
| General Properties | |
|---|---|
| Below we list the number of gene sets from which the module was composed was originally composed, and the number of genes and experiments that it contains. Clicking on the number of genes will display a detailed list of all the genes in the module. Clicking on the number of experiments will display a detailed list of all the experiments in the module. | |
| Num gene sets: | 4 |
| Num genes: | 18 (see 391 additional genes for this module) |
| Num experiments: | 83 (49 induced, 34 repressed) |
| Parent module: | 457 |
| Children modules: | None |
| Gene sets | |
|---|---|
| Below we list the gene sets from which the module was originally composed. Clicking on a gene set will display all the genes associated with that gene set. Also listed are all the other modules in which the gene set participates. | |
| rRNA processing | |
| chromosome organization and biogenesis (sensu Eukarya) | |
| nucleolus | |
| damaged DNA binding | |
| Enriched clinical annotations | |||||||
|---|---|---|---|---|---|---|---|
| For each of the clinical annotations, we tested whether it was enriched in the set of arrays in which the module is significantly induced (or repressed). Below we list all such annotations that were enriched in this module with an FDR corrected p-value of 0.05 ('P-value' column), along with the number ('Hits' column) of induced (or repressed) module's arrays in which they appear. We also show the fraction of the module's induced (or repressed) arrays with the given annotation ('Hits (%)' column). For completeness, we also list the total number of relevant induced arrays in the module ('Module hits in category' column), total number of arrays in the compendium in which the corresponding annotation is present ('Arrays in annotation' column), and the total number of relevant arrays in the compendium ('Arrays' column). Note that the 'relevant' arrays may be different for each annotation, since it includes only arrays in which the annotation was relevant (i.e., present or not present) and excludes arrays where the value of the annotation was not known. Rows that correspond to annotations that were enriched in the induced arrays of the module have a red background, while rows corresponding to annotations enriched in the repressed arrays have a green background. For each annotation, we also list the other modules in which it was enriched. | |||||||
| Clinical annotation | Category | P-value | Hits | Hits(%) | Module hits in category | Arrays in annotation | Arrays |
| Normal lung tissue (Lung cancer) | Lung cancer | 1.2e-07 | 6 | 100 | 6 | 22 | 276 |
| Normal tissue (Lung cancer) | Lung cancer | 1.7e-07 | 6 | 100 | 6 | 23 | 276 |
| Breast tissue or cancer (NCI60) | NCI60 | 3.3e-07 | 4 | 80 | 5 | 4 | 139 |
| Female hormonal tissue or cancer (NCI60) | NCI60 | 3.3e-07 | 4 | 80 | 5 | 4 | 139 |
| Liver cancer cell line (Liver cancer) | Liver cancer | 8.8e-06 | 6 | 40 | 15 | 10 | 207 |
| Cell line (Liver cancer) | Liver cancer | 1.8e-05 | 6 | 40 | 15 | 11 | 207 |
| Breast cancer (NCI60) | NCI60 | 2.2e-05 | 3 | 60 | 5 | 3 | 139 |
| Liver tissue, cancer or cell line (Liver cancer*) | Liver cancer* | 0.0002 | 14 | 28.5 | 49 | 197 | 1945 |
| Cancer and cell line (Liver cancer) | Liver cancer | 0.0004 | 15 | 100 | 15 | 126 | 207 |
| Breast tissue, cancer or cell line (NCI60) | NCI60 | 0.0004 | 5 | 100 | 5 | 31 | 139 |
| Enriched GO annotations | ||||||
|---|---|---|---|---|---|---|
| For each GO annotation, we tested whether it was enriched in the set of genes of the module. Below we list all such annotations that were enriched in this module with an FDR corrected p-value of 0.05 ('P-value' column), along with the number ('Hits' column) of the module's genes in which they appear. We also show the fraction of the module's genes with the given GO annotation that are included in this module ('Hits (%)' column). For completeness, we also list the total number of genes in the module ('Module genes' column), total number of genes in the compendium in which the corresponding annotation is present ('Genes in annotation' column), and the total number of genes in the compendium ('Genes' column). | ||||||
| GO annotation | P-value | Hits | Hits(%) | Module genes | Genes in annotation | Genes |
| nucleolus | 1.0e-14 | 9 | 50 | 18 | 43 | 4566 |
| DNA metabolism | 3.2e-12 | 11 | 61.1 | 18 | 169 | 4566 |
| chromosome organization and biogenesis (sensu Eukarya) | 4.7e-10 | 7 | 38.8 | 18 | 52 | 4566 |
| chromatin assembly/disassembly | 2.2e-09 | 6 | 33.3 | 18 | 35 | 4566 |
| establishment and/or maintenance of chromatin architecture | 1.2e-08 | 6 | 33.3 | 18 | 46 | 4566 |
| damaged DNA binding | 2.1e-08 | 5 | 27.7 | 18 | 24 | 4566 |
| chromatin | 2.1e-08 | 6 | 33.3 | 18 | 50 | 4566 |
| DNA packaging | 2.1e-08 | 6 | 33.3 | 18 | 50 | 4566 |
| nuclear chromosome | 6.5e-08 | 6 | 33.3 | 18 | 60 | 4566 |
| chromosome | 8.0e-08 | 6 | 33.3 | 18 | 62 | 4566 |
| ribonucleoprotein complex | 3.5e-07 | 9 | 50 | 18 | 283 | 4566 |
| viral genome | 6.3e-07 | 4 | 22.2 | 18 | 19 | 4566 |
| response to DNA damage stimulus | 7.7e-07 | 9 | 50 | 18 | 310 | 4566 |
| nuclear chromatin | 7.8e-07 | 4 | 22.2 | 18 | 20 | 4566 |
| virion | 9.7e-07 | 4 | 22.2 | 18 | 21 | 4566 |
| nucleosome disassembly | 1.1e-06 | 4 | 22.2 | 18 | 22 | 4566 |
| nucleolar preribosome | 1.7e-06 | 4 | 22.2 | 18 | 24 | 4566 |
| nucleosome assembly | 1.7e-06 | 4 | 22.2 | 18 | 24 | 4566 |
| DNA repair | 2.1e-05 | 5 | 27.7 | 18 | 93 | 4566 |
| Visual display | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Below is a visual display of the module. Shown are those arrays in which the module's genes significantly change, and the direction of change (induction/repression) in each array is indicated (middle, labeled 'Module changes'; red/green row). The arrays that correspond to the significant clinical attributes are also shown (top; brown rows). The gene sets that compose the module are also shown (left) along with an indication of the membership of the module genes in these gene sets. | |||||||||
| You can also view the images within GeneXPress by loading the module gxp file file. | |||||||||
|
|||||||||


