Clustering Using Distinctive Component Analysis(DCA)
Salih Burak Gokturk
Distinctive Component Analysis has not been originally designed for blind source seperation problem (unsupervised clustering). However, one can still use it for this purpose. In this report, we give an algorithm for the application of Distinctive Component Analysis to the clustering problem with known number of clusters.
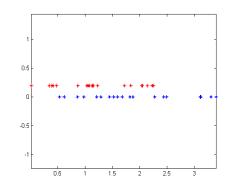
DCA needs two labeled classes in the training set. However, in unsupervised clustering, we do not have the labels for the training set. Thus we have to be able to invent labels and two classes to apply DCA on them. One strategy is to get the current clusters and use them as the training data. On the other hand, by DCA, we aim to correct the errors in clustering, i.e. similar to the ones given in Figure 1(b), thus taking as DCA input the two clusters as a whole might probably confuse DCA in getting the distinctive components.
Figure 1(a) Figure 1(b)
In Figure 1(a), we illustrate two sets that are easy to distinguish. However, when an Euclidean distance based distance measure is used in k-means algorithm, the clusters are not identified correctly as given in Figure 1(b). By the addition of DCA, we aim to correct errors similar to this one. More specifically, in our iterations, we will assume that a point x is wrongly labeled. To be able to distinguish that, two sets will first be identified as follows: Set 1 - A set in the same cluster (current cluster) with x, with elements as far as possible from x in Euclidean distance. Set 2 - A set in the other (neighbor if more than 2 clusters) cluster with elements as close as possible to x in Euclidean distance. DCA is next applied to these two sets. Let m1 and m2 be the average projection of the two sets. Once Distinctive Component (α) is found using these two sets, it is applied on all of the data points on both of the clusters. The overall algorithm is given as follows:
1- Initialization: Start with an initial selection of codewords. We chose the two initial codewords in the direction of principal components in this analysis. Let Vi be the codewords (cluster centers).
2- Assign each data point x, to the cluster i, where the distance measure d(x,Vi) is the smallest among all clusters. The distance measure is given as a Lagrangian formulation that contains the Euclidean distance, and the DCA distance as follows:
![]()
where λ is Lagrangian and DCA(x,Vi) is given as:
![]()
where m0 is the average of m1 and m2. α is found for one point as described above and applied to all points. DCA should be applied to the two neighbor clusters if there are more than two clusters.
3- Update the cluster centers Vi as the centroids of the cluster i.
4- Repeat 2 and 3 until convergence of clusters.
Experiments
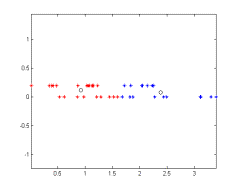
The given algorithm is applied on a two class clustering problem. All of the iterations of the algorithm are given below. The iterations converge to the correct identification of the two clusters. On the figures, the black and red dots give the two cluster data points, and the blue circles give the cluster centers.
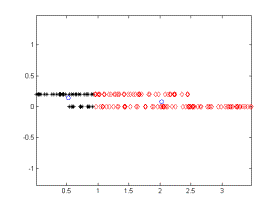
Iteration - 1 Iteration - 2 Iteration - 3
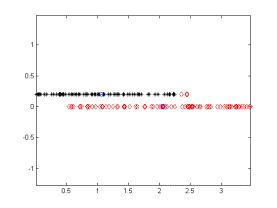
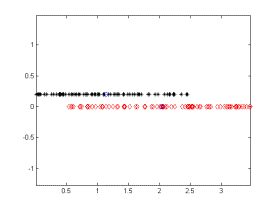
Iteration - 4 Iteration - 5
Figure 2.Iterations of the algorithm
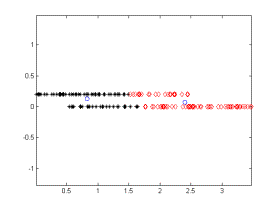
To evaluate the system for less obvious clusters, we added Gaussian random noise to each data point. Figure 3 demonstrates an example with Gaussian noise of 0 mean and 0.05 standard deviation. In this example, the noise was too much for DCA to identify two parallel lines. A close look shows that the random distribution of the points have formed another distinctive component and the algorithm picks this distinction.
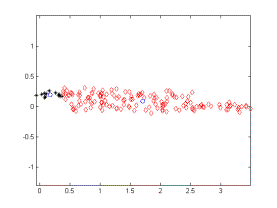
Figure 3. An example where N(0,0.05) is added as noise.
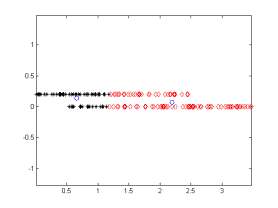
Figure 4 gives another example where a Gaussian with 0.01 standard deviation was used. In this example the distinctive components are clearly identified but with a cost of more iterations (15).
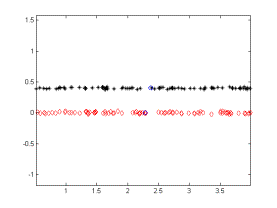
Figure
4. An example where N(0,0.01) is added as noise.
Currently, the experiments are applied on two class clustering problem. Future investigation will involve application of DCA to more than 2 class unsupervised clustering problems. We think that, the given algorithm is still valid, with the slight change that when testing a point x, DCA is applied between the two closest neighbor clusters to x.
You can get the code for a little demo here. Put the two files to a directory and run DCA_DEMO in Matlab.