Car Dataset Results
This page includes:
Testing Set
Below are the results we obtained by running our segmenter on the 8
scenes in our testing set.
Testing Set Results (SVM)
Quantitative AMN to SVM comparison:
[2] A. Johnson and M. Hebert. Using spin images for efficient object recognition in cluttered 3D scenes. In IEEE PAMI, volume 21, pages 433-449, 1999.
- Section
from the paper describing the data and the models
- Training
set pictures
- Testing
set pictures
- Comparison
to Support Vector Machines
Description
|
|
Overview We also tested our method on a set of artificially generated scenes. These scenes contain instances of different types of vehicles, trees, houses, and the ground. Models of the objects in these scenes were obtained from the Princeton Shape Benchmark[1], and were combined in various ways. From these, a set of synthetic range scans were generated by placing a virtual sensor inside the scene, and casting rays to determine the scan distance in each direction. We corrupted the scan readings with additive white noise. We then triangulated the resulting point cloud, and subsampled down to our desired resolution. Point Features We used the same features (spin-images) [2] as the ones we used in the puppet dataset, but adjusted to the size of the objects in this dataset. Edge Features We use the surface links output by the scanner as edges in the MRF. We obtained the best results by using a single bias feature (set to 1 for all edges). |

Training Set
We used a training set of 5 labeled scenes involving models of different vehicles, houses and trees. Below we display the performance of the Maximum-margin AMN algorithm on the training set.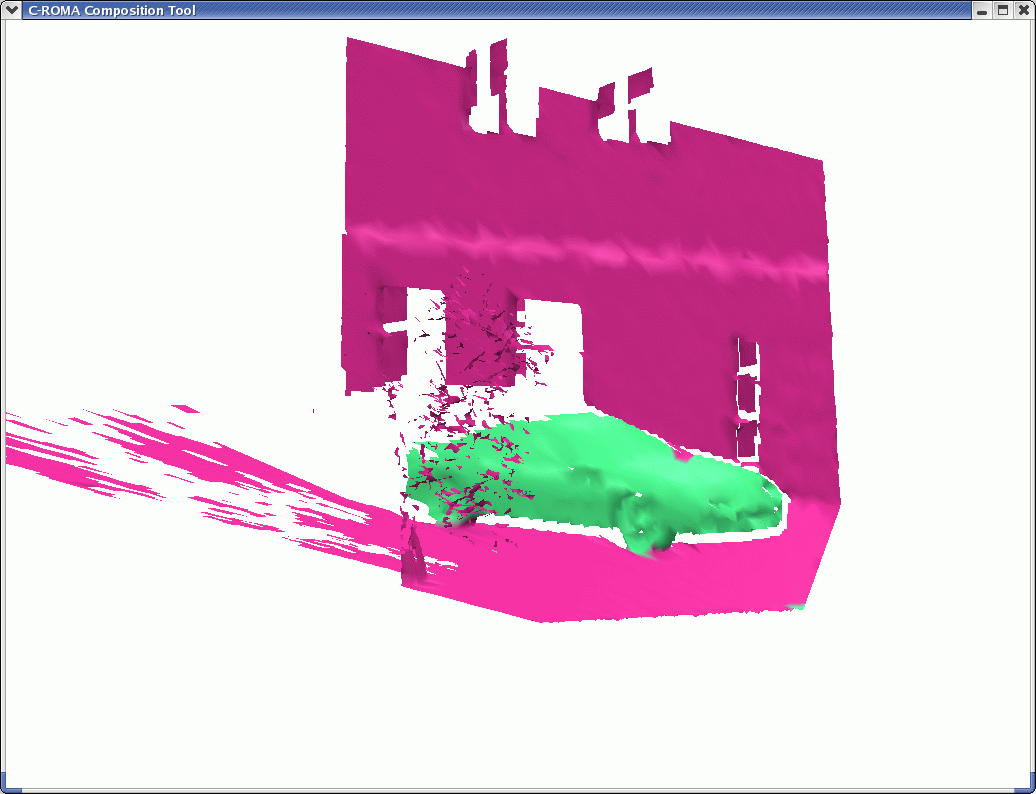 Scene 1 |
 Scene 2 |
 Scene 3 |
 Scene 4 |
 Scene 5 |
{kind=link}
Testing Set
Below are the results we obtained by running our segmenter on the 8
scenes in our testing set.  Scene 1 |
 Scene 2 |
 Scene 3 |
 Scene 4 |
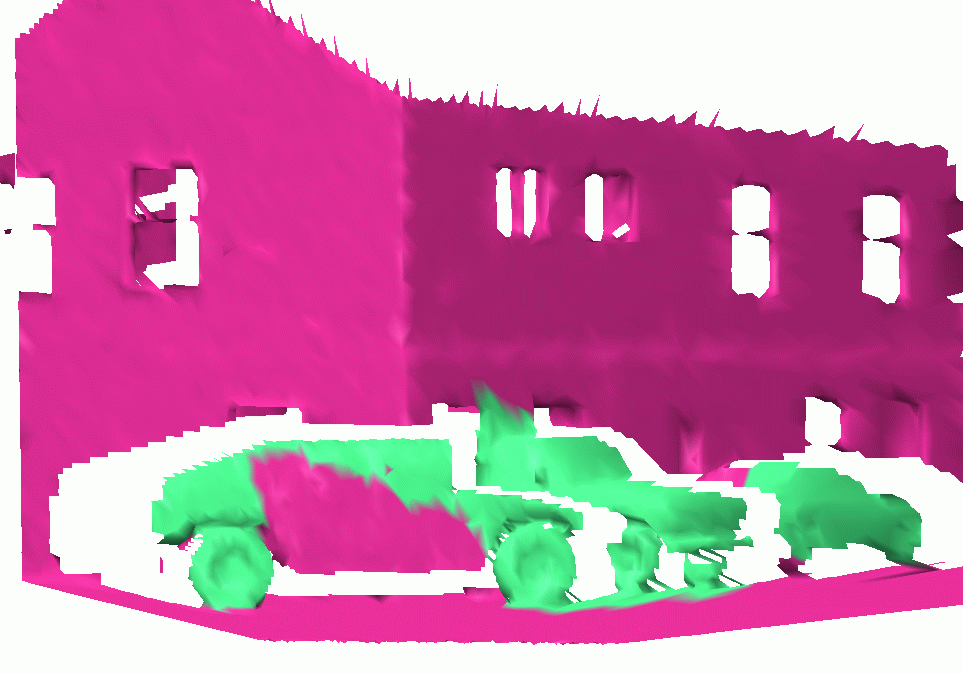 Scene 5 |
 Scene 6 |
 Scene 7 |
 Scene 8 |
Comparison to SVM
We compared our Maximum-margin Associative Markov Nets (MM-AMN) method to Support Vector Machines which classify each scan point separately (SVM). Below we the results of using SVMs instead of AMNs on the same training-testing sets and the same features:Testing Set Results (SVM)
 Scene 1 |
 Scene 2 |
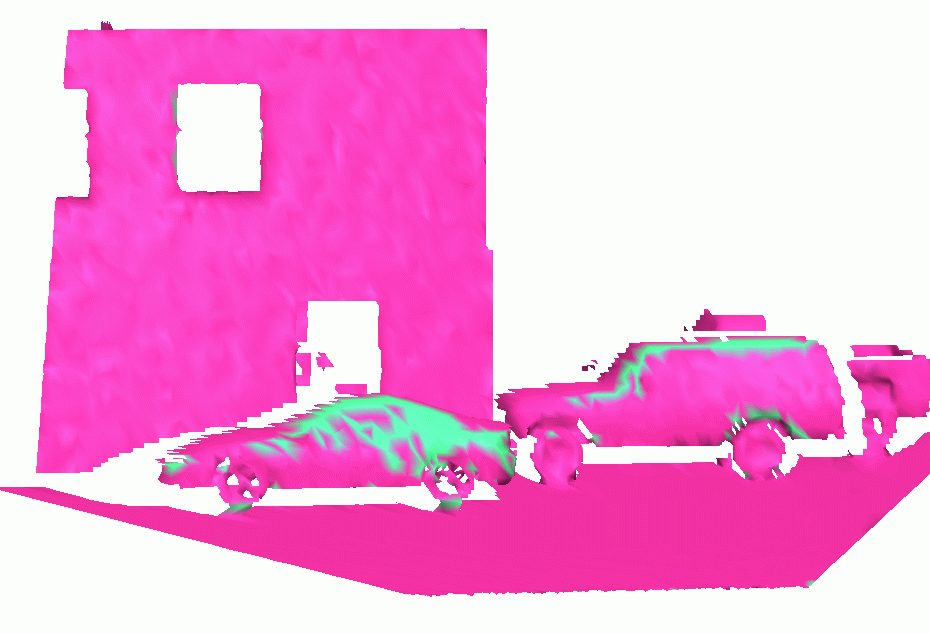 Scene 3 |
 Scene 4 |
 Scene 5 |
 Scene 6 |
 Scene 7 |
 Scene 8 |
Quantitative AMN to SVM comparison:
| Results |
AMN |
SVM |
| Training set accuracy |
98.41% | 88.90% |
| Testing set accuracy |
93.76% | 82.23% |
| Precision on testing set |
93.60% |
89.35% |
| Recall on testing set |
75.29% | 17.05% |
Bibliography
[1] P. Shilane, P. Min, M. Kazhdan, and T. Funkhouser. The Princeton Shape Benchmark. In Shape Modeling International, 2004.[2] A. Johnson and M. Hebert. Using spin images for efficient object recognition in cluttered 3D scenes. In IEEE PAMI, volume 21, pages 433-449, 1999.